
Science is a systematic exploration of data. Data can be acquired in various ways such as using sensor devices, social media, customer records and other input devices. The main challenge of data science is how to explore insightful knowledge from such data so that we can use this information for our benefit. For example, if you are using Facebook – one of the popular social networking sites – and you do like, share and comment on the different posts that appear on your wall, by these activities, Facebook collects data about your choice, preference and behavior. On the basis of information obtained by processing such data, Facebook generates or sends sponsored posts or events on your wall so that you might like those posts or events and prefer to click on such posts or events. This is an example of data exploration. To explore insightful knowledge from data, we need to process it systematically. This is also known as a data processing pipeline.
Introduction
Machine learning is the use of intelligent algorithms to extract useful patterns from data. According to Tom Mitchell, “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E”
Machine learning is different from traditional computer programming. In machine learning we do not write each and every rule as a program code but the computer will be able to figure out the needed rule or pattern by scanning input data as shown in Figure 1. Therefore, data is the essential raw material for any machine learning system. To prepare the data for machine learning algorithms, we need to process, explore and visualize such data as a part of data science. So, machine learning and data science are inter-connected like both sides of a coin.
How Machines Learn
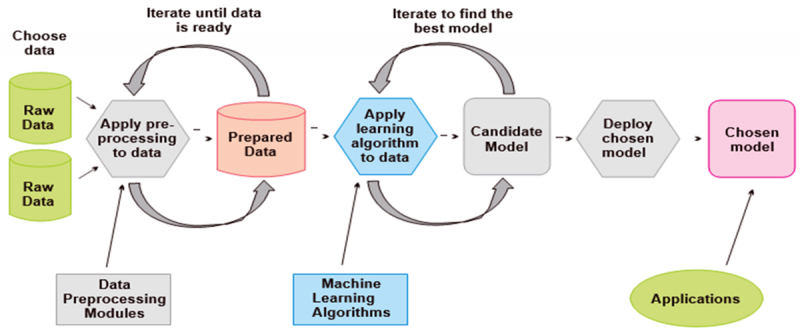
Machine learning works in a pipeline of different activities as shown in Figure 2. It first needs data to be feed into the system where the data gets pre-processed. The preprocessing of data consists of removing noise and making it fit for appropriate formatting. This process continues until the data gets ready for machine learning models. Machine learning engineers now use preprocessed data to design an appropriate machine learning model and implement as well as test it. After these activities, the machine learning model is deployed in real-time applications (RTA).
Opportunities in Machine Learning and Data Science
In the 6th Edition of the World Economic Forum (WEF) held in Switzerland last year, the term ‘Data Scientist’ was listed as the most demanding profession in the world. We can see how widespread and expanding this field is now. Why it has become so widespread is because many devices are now connected to the Internet because of the Internet. Each day, users are feeding some data or the other to the Internet. Like social media or search engines, data is reaching big software companies. These companies consider this data as fuel. The demand for data scientists has increased in the market due to the availability of sufficient data for extracting information and getting useful output. The services of data scientists are especially used in digital marketing and commercial advertising. For example, data scientists can analyze image data through image processing. They can discern whether there is water on Mars or other planets, or whether there are other specified things. One such development is the latest visualized information on the ‘black hole’. This too is an extraordinary achievement of data science. The image of the black hole they have created, is not a real image captured by image acquisition tools but a computer-generated image after due processing of select data. Banks too can greatly use data science. Today, nearly all-important banks have digitized data. Computerized data is used by banks and financial institutions in order to launch new schemes through data analysis or through data synthesis to boost business. Data science seems to have become a routine process there.
Challenges in Machine Leaning and Data Science in Nepal
The main challenge on how to start up machine learning and data science businesses in Nepal is the lack of experts in these fields. Our universities as yet have no specific courses dealing with these subjects individually but only as a part of full courses – BIM or BIT – comprising Computer Science & IT, Computer Engineering, or Information Technology. We first need to build the right environment for machine learning and data science in our country. For this, the like-minded – professionals, teachers, and educators – need to come together to work and share available opportunities with students. Another challenge is the scarcity of computing resources. Most educational institutions do not have their own high-performance computers, and servers, which are essential components of big data analysis and data science. However, there is the availability of cloud computing where we can buy computing resources as per our requirements even though these resources may not be as reliable as those available through our own servers.
Conclusion & Recommendations
We have numerous opportunities being a developing country because there is much to be automatized in Nepal in almost every sector such as online ticketing in transportation, digital health in health services, e-governance in the offices of Nepal Government. The government must establish a computing research center which can devise new technological applications or even the technology related to information technology, machine learning and data science. We, as educators, should start designing new courses and developing new curricula to empower our students with the knowledge of data science and machine learning. In future, the automation of these fields requires not only such inputs of modern information technology but also the use and development of artificial intelligence (AI) along with machine learning and data science.
References
Mitchell T, Carbonell J et al (2012). “Machine learning: a guide to current research”, Kluwer Academic Publishing.
Grus J (2019). “Data Science from Scratch”, Second Edition, Orally Publisher, USA
The Authors: Mr Tej B Shahi & Mr Surya B Basnet are the founder members of Machine Learning and Data Science Community Nepal (MLDSN). (www.mldsn.org)


